
WebScraper for Mac 4.4.0 快速扫描网站
WebScraper使用Integrity v8引擎快速扫描网站,并可以将提取的数据(当前)以CSV或JSON格式输出。 Plus将图像下载到文件夹。
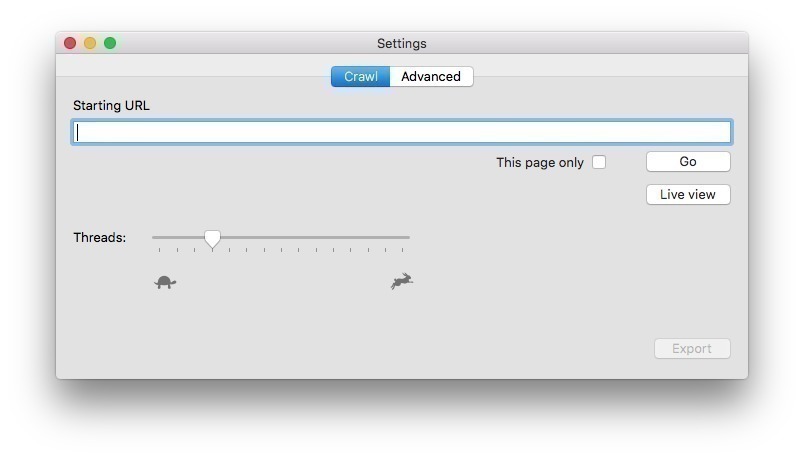
易于扫描网站 - 只需输入起始网址并按“开始”
易于导出 - 选择你想要的列
大量提取选项,包括具有特定类或ID的HTML元素,正则表达式或多种格式的全部内容(html,纯文本,降价)
由于v4.1可以将所有发现的图像下载到文件夹中
配置爬网和输出文件大小的各种限制
更多…
版本4.2.0:
改进了“输出文件列构建器”表 - 列与列以前一样显示在列中,因此希望更易于使用。您可以通过拖动列来重新排列它们,编辑它们的标题,编辑该列的配置或删除列。
改进输出文件过滤器(以前称为'信息页面包含')。现在可以将其视为“选择哪里”,并允许设置多个规则,并且或者或。这些可以基于'包含'部分匹配或正则表达式。每个规则的更多选项(如包含/不包含)以及将规则应用于url或整个内容。
添加一个适当的链接表,这可以用来收集/列出路上发现的所有链接目标网址,也可以选择映像网址。此列表可以过滤只是链接/只是图像/内部/外部/重定向/ pdf文件
添加能够轻松提取具有特定类/ id的标题(h1-h7)(之前,类或id方法仅限于div,span,p和dd)
更改显示在地址栏右侧的“计数”。现在它实际上显示了在输出表中哪些=行的scraped页数。以前它是发现的页数,现在可能不是相同的数字,因此您可以制定充当输出过滤器的规则。
修复了最近引入的错误,该错误阻止了您的输出列在保存的项目中正确保存
Screenshot 软件截屏:
System requirements 系统要求:
- OS X 10.7 or Later
下载地址:
相关下载:


















